Data breaches cost organizations an average of $4.45 million per incident, according to IBM’s 2024 report. Most of these incidents stem from poor data handling practices and unclear security protocols.
At Scan N More, we’ve seen firsthand how organizations struggle when they lack proper data security classifications. Without a clear system for categorizing and protecting information, companies expose themselves to unnecessary risk and regulatory penalties.
What Data Classification Actually Means
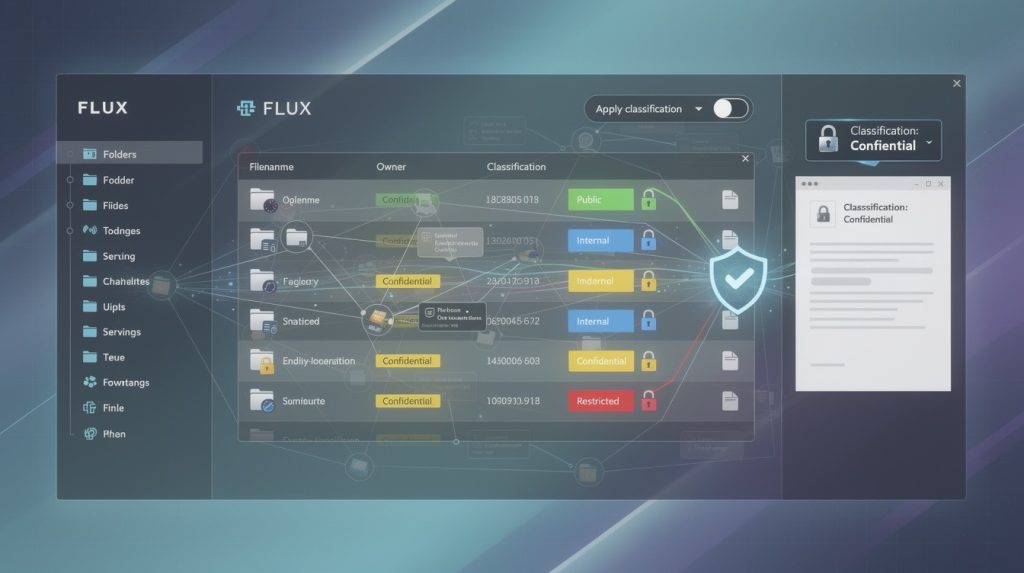
Data classification sorts information into categories based on sensitivity, regulatory requirements, and business value. It answers one fundamental question: what information needs protection and why? Organizations handle vastly different types of data daily. Customer records, financial statements, employee information, and scanned legal documents all carry different levels of risk. Classification forces you to identify which data matters most and what happens if it leaks.
The most common classification structure uses four levels. Public data can be freely shared without consequence-think marketing materials or published company announcements. Internal Use data should stay within your organization but doesn’t require heavy protection-department memos or general business information fit here.

Restricted data demands serious attention because unauthorized access creates real problems (customer personally identifiable information, financial records, and proprietary business plans). Confidential data represents your highest-risk category: social security numbers, health records, legal documents, passwords, and trade secrets. Each level requires proportional security controls, which is why classification matters operationally.
Why Organizations Skip This Step
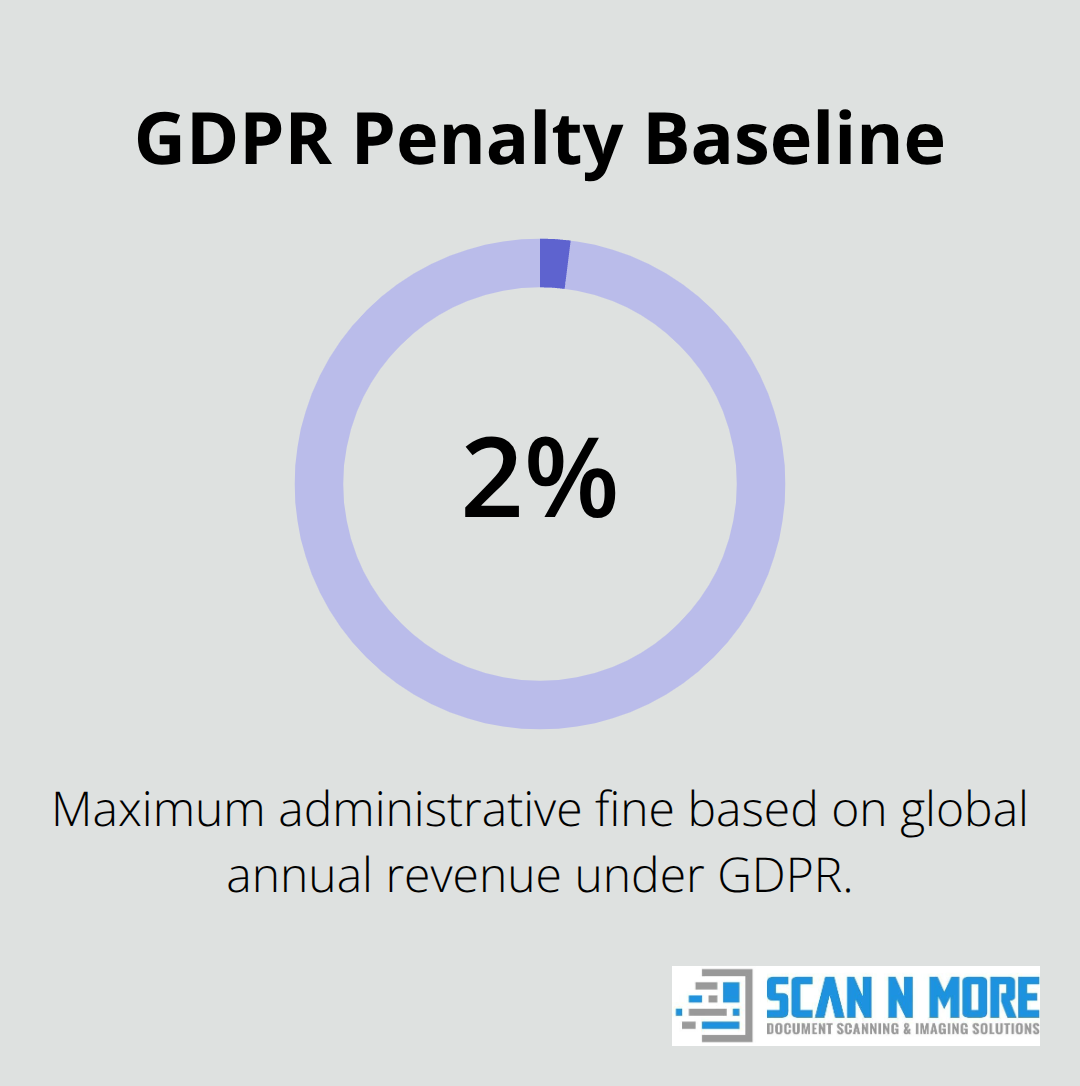
Many organizations resist data classification because it feels abstract until a breach happens. The reality is stark: GDPR violations carry penalties up to €10 million, or 2% of global revenue. HIPAA breaches of protected health information average $408 per compromised record, based on data from the Department of Health and Human Services. PCI DSS noncompliance results in fines ranging from $5,000 to $100,000 monthly. These aren’t theoretical risks-they’re financial consequences that executives understand immediately.
Classification also solves operational problems. When your team knows which data is confidential, they make better decisions about storage, sharing, and access. You reduce duplicate efforts, eliminate unnecessary backups of low-value data, and focus security investments where they actually matter. Organizations that implement classification report faster incident response times because they already know what’s sensitive and where it lives.
How Classification Connects to Real Security
Classification alone doesn’t protect anything-it’s the foundation for everything else. Once you’ve classified data, you apply matching security controls. Confidential data gets encryption both at rest and in transit. Restricted data needs strong access controls and audit logging. This proportional approach means you’re not spending equally on all data; you’re investing heavily where it counts.
Many organizations make the mistake of treating all information the same, which either creates security theater around low-risk data or leaves sensitive data unprotected. Classification prevents both problems. It also simplifies compliance conversations with regulators and auditors. When you can point to a documented classification system and show how you’ve applied controls accordingly, you’ve already addressed most compliance questions. Regulators care less about perfect security and more about demonstrating that you’ve thought through your data, identified risks, and applied reasonable protections.
Moving Into Implementation
Understanding what classification means is one thing; actually building a system that works is another. The next section walks through how to assess your current data inventory and start assigning classification levels that match your organization’s actual risk profile.
Building Your Data Inventory and Classification System
Start With What You Actually Have
Start with what you actually have, not what you think you have. Most organizations fail at classification because they skip the inventory phase and jump straight to assigning labels. The National Institute of Standards and Technology emphasizes that you cannot classify data you haven’t found. Identify where data lives across your environment: file servers, cloud storage, databases, email systems, and scanning systems if you work with paper documents. This isn’t a one-time audit-data grows constantly, so treat inventory as an ongoing process.
Many organizations discover that during this phase, according to research from Gartner. That’s money wasted on storage and backup for information nobody needs. The inventory process forces you to confront what you’re actually keeping and why.
Map Your Highest-Risk Data Types First
When you assign classification levels, tie each decision directly to regulatory requirements and business impact rather than guessing. Start with your highest-risk data types: personally identifiable information like social security numbers and addresses, protected health information if you handle medical records, payment card data, financial records, and trade secrets. These map to Confidential or Restricted classifications because the regulatory consequences are severe.
If you operate in healthcare, HIPAA requires you to track who accesses health records and when. If you process payments, PCI DSS mandates encryption for cardholder data. These regulations aren’t suggestions-they’re your classification roadmap. For data that doesn’t trigger regulatory requirements, ask what happens if a competitor gets it or if it becomes public. Customer email addresses might seem low-risk until you realize competitors could use them for targeted attacks. Proprietary pricing models absolutely deserve Confidential status. The key is making classification decisions based on real consequences, not assumptions.
Document Your Classification Taxonomy
Document these decisions in a simple taxonomy that your team can actually remember and follow. If your classification system requires a 50-page manual to understand, people will ignore it. Establish clear handling rules for each classification level and document them formally. Confidential data requires encryption at rest and in transit, limited access to specific roles, and audit logging of every access. Restricted data needs strong authentication and role-based access controls. Internal Use data can have broader access but should still be restricted to employees. Public data needs no special handling but should be marked clearly so nobody accidentally treats it as sensitive.
The documentation matters because it removes interpretation from the process. When someone asks if they can email a spreadsheet to a vendor, they can check your policy instead of guessing.
Define Handling Rules Across the Data Lifecycle
Your policy should specify how to handle data across its lifecycle: creation, storage, sharing, and deletion. Include specific guidance on cloud storage, email, and file sharing tools since those are where most exposure happens. Make someone responsible for maintaining and updating this documentation annually because regulations change and new data classification levels emerge constantly.
Once you’ve documented your classification system and handling rules, the next critical step involves putting these policies into action across your organization. This requires training your team on what these classifications mean and why they matter to daily operations.
Keeping Your Classification System Alive and Effective
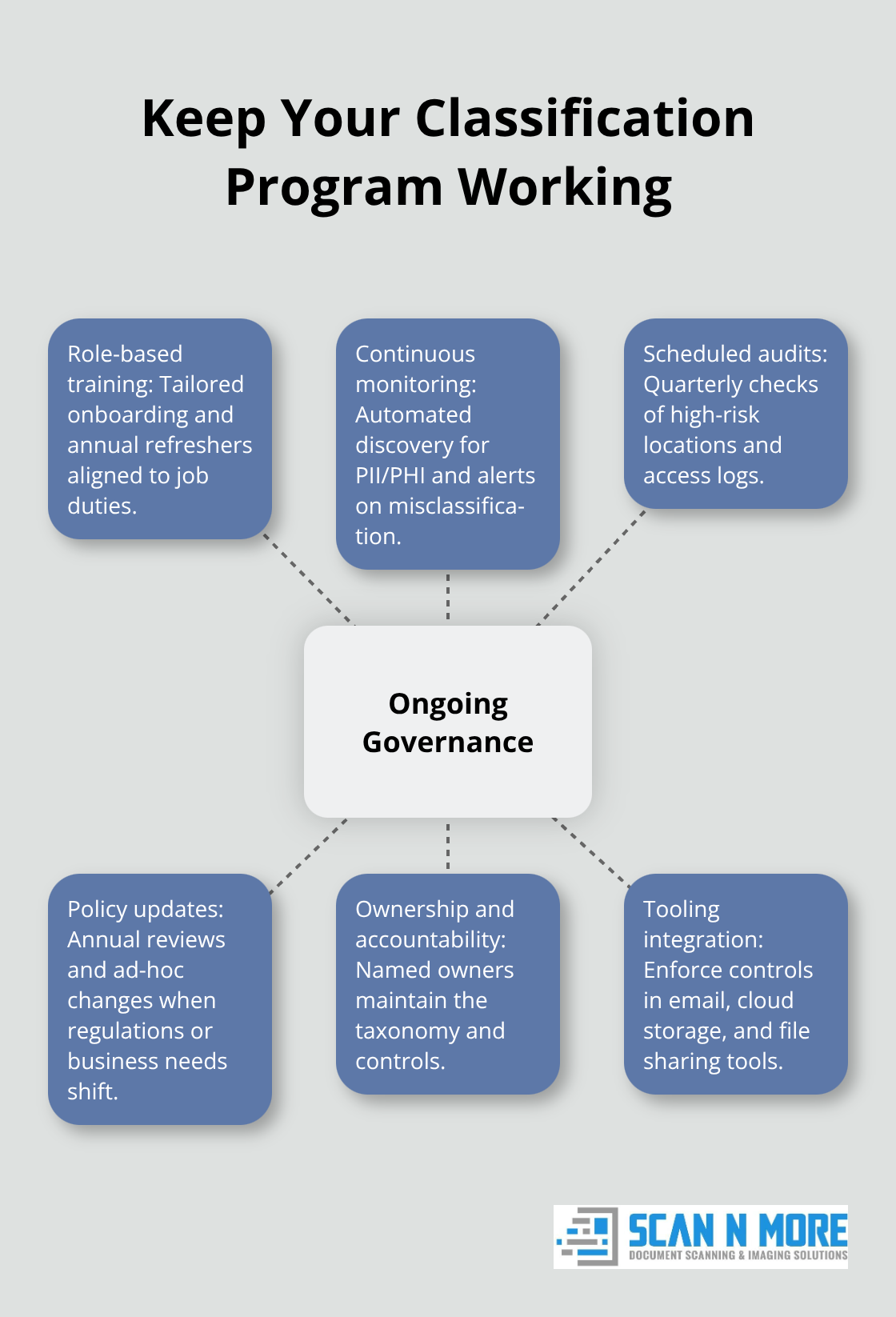
Your classification system only works if people actually use it consistently, and that requires ongoing investment in training, monitoring, and updates. Most organizations treat classification as a one-time project rather than an operational practice, which is why their systems fail within six months. Classification demands continuous effort because your data landscape changes constantly.
New applications get deployed, team structures shift, regulations tighten, and employees rotate into roles they don’t fully understand. Without active maintenance, classification becomes outdated and people stop trusting it.
Train Your Team on What Classification Means
Start with initial training that goes beyond a generic security awareness video. Your team needs to understand why classification matters to their specific job. A finance employee handling customer payment data needs different training than someone managing internal project files. Show them real examples from your organization: this spreadsheet is Confidential because it contains pricing data; this folder is Restricted because it holds customer information subject to GDPR.
Make training mandatory during onboarding and refresh it annually because compliance regulations like HIPAA and PCI DSS require documented staff training. Track who completed training and when because regulators will ask for this evidence during audits. Use your classification taxonomy in training materials so people see the same language and definitions consistently.
Monitor and Audit Your Data Regularly
Monitoring and auditing comes next, and this is where most organizations cut corners despite it being non-negotiable. Set up automated tools to scan your file systems, cloud storage, and email for sensitive data that’s been misclassified or left unprotected. Tools that identify personally identifiable information and protected health information catch mistakes that manual review would miss.
Conduct quarterly audits of high-risk data locations to verify that Confidential and Restricted information actually follows your policies. Check access logs to see who touches sensitive data and whether access aligns with their role. If a marketing employee suddenly accesses financial records, that’s a red flag worth investigating. Document all audit findings and corrections because this demonstrates due diligence to regulators.
Update Classifications as Your Business Evolves
Update your classification decisions annually at minimum, more frequently if your business changes significantly. When new regulations emerge or your organization enters a new industry vertical, review whether your existing classifications still map correctly to actual risk. A data classification system that worked two years ago might be inadequate today (especially if you’ve added new data types or expanded into regulated industries).
Make this review a formal process with documented decisions and ownership assignments so it doesn’t get deprioritized when other urgent work appears. Assign someone responsibility for maintaining and updating this documentation because regulations change and new data classification levels emerge constantly. Your policy should specify how to handle data across its lifecycle: creation, storage, sharing, and deletion. Include specific guidance on cloud storage, email, and file sharing tools since those are where most exposure happens.
Final Thoughts
Implementing data security classifications requires three concrete steps that separate organizations that actually protect their data from those that pretend to. First, complete a full inventory of where your data lives and what you’re storing, then assign classification levels based on regulatory requirements and real business consequences, not assumptions. Second, document your handling rules clearly enough that your team can follow them without constant interpretation. Third, treat classification as an ongoing operational practice rather than a one-time project by training employees, auditing regularly, and updating your system annually as your business evolves.
Organizations that follow this approach see measurable benefits within months. Your incident response times improve because you already know what’s sensitive and where it lives. Compliance conversations with regulators become straightforward because you can demonstrate a documented system with proportional controls. You stop wasting money on unnecessary backups and storage for data nobody needs.
If your organization still handles paper documents alongside digital files, data security classifications become even more critical. Scan N More provides professional document scanning services that transform paper-based processes into secure digital solutions, ensuring your scanned documents receive the same classification and protection as your digital data. Start your implementation this month, not next quarter, because the cost of a single data breach far exceeds the effort required to build a working classification system.